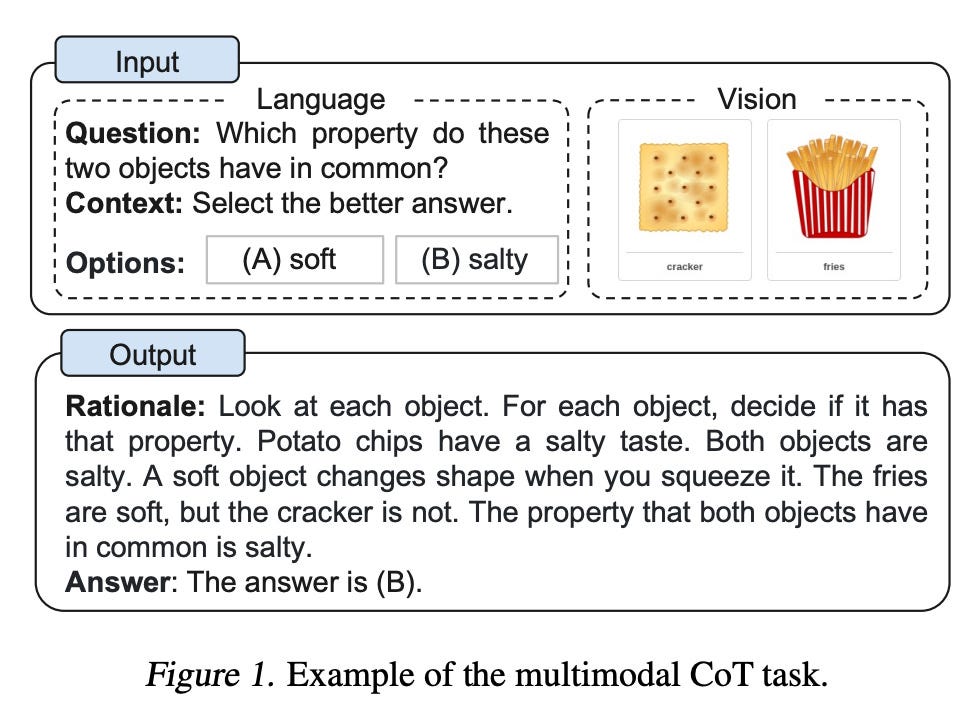
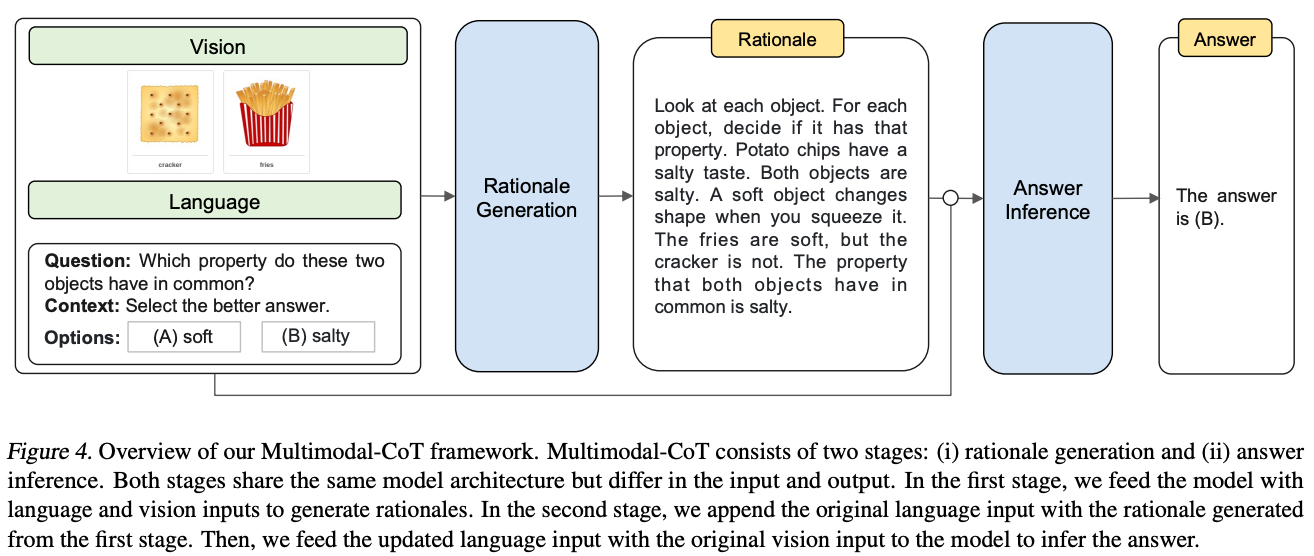
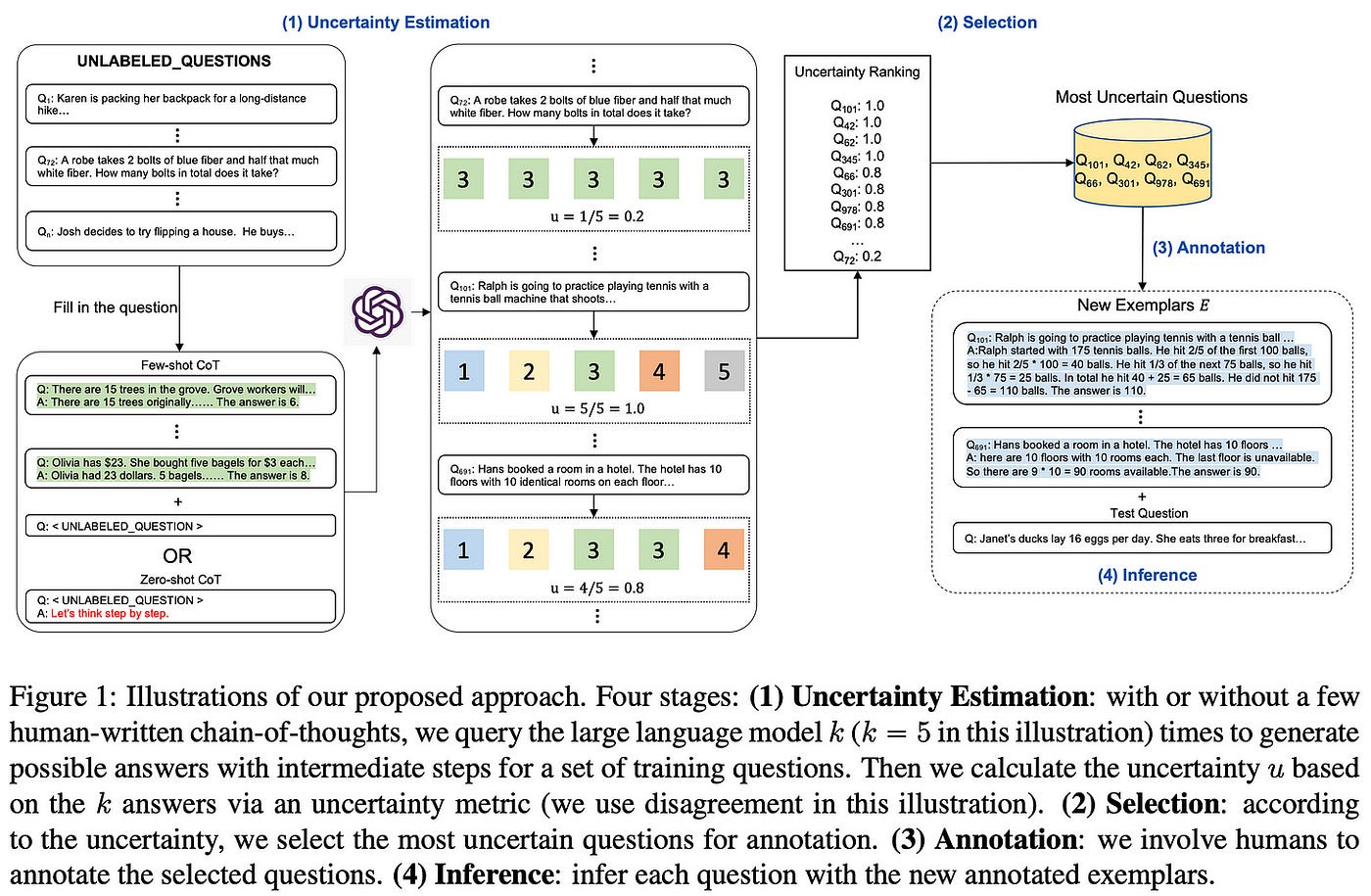
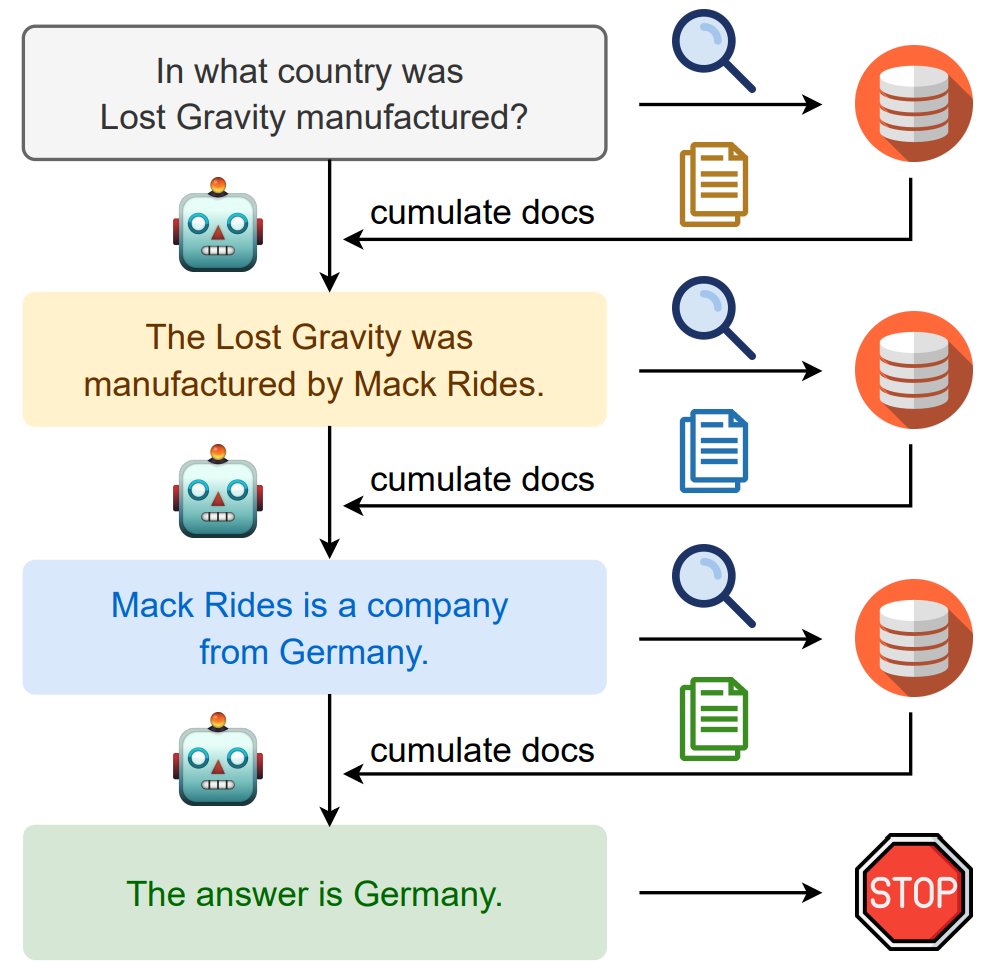
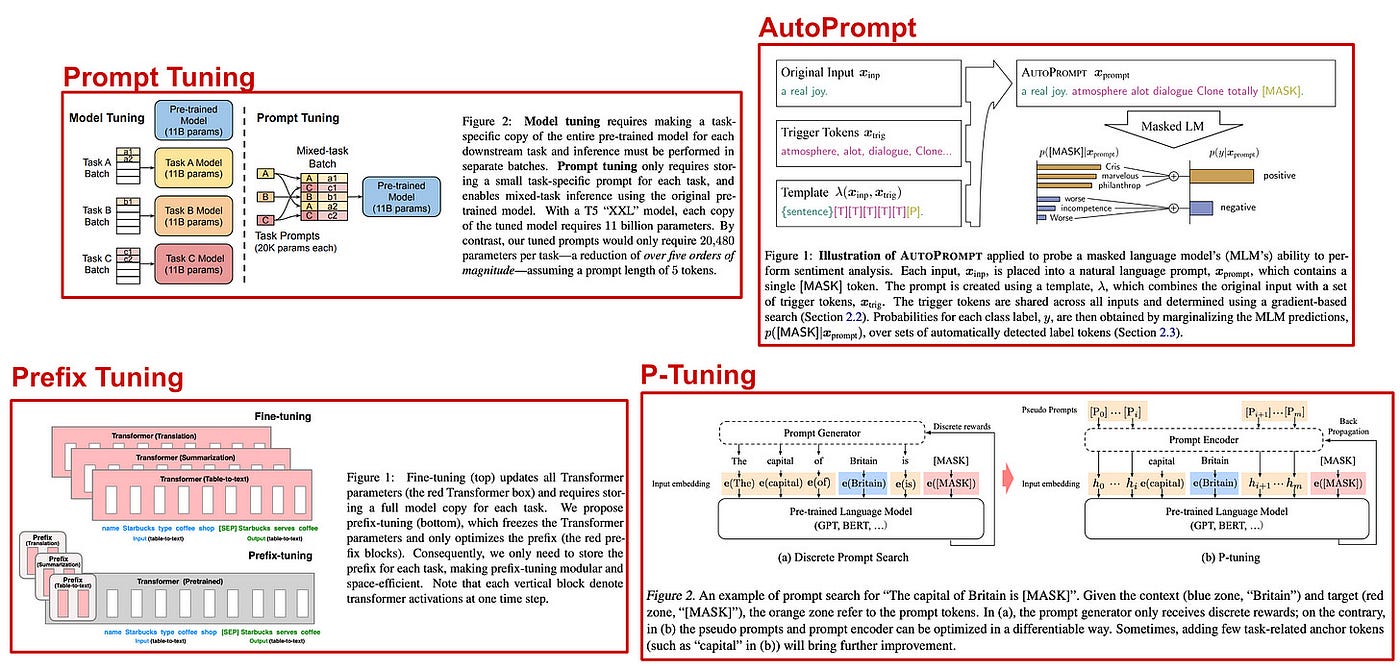
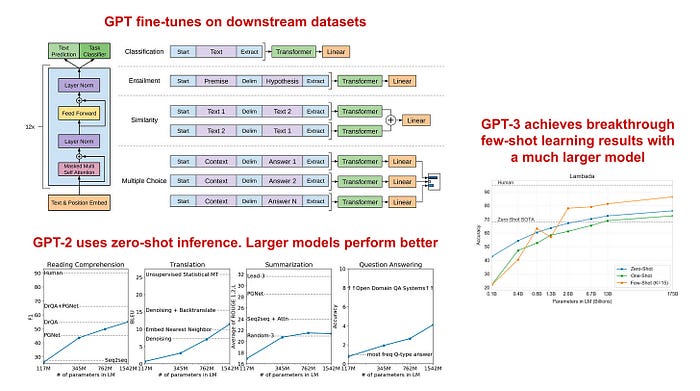
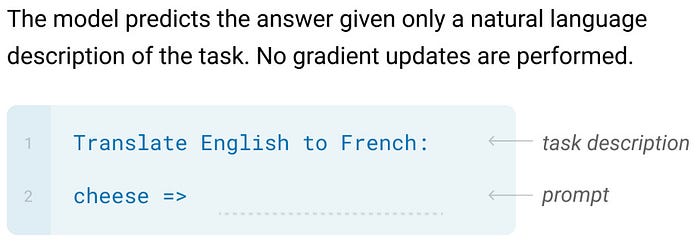
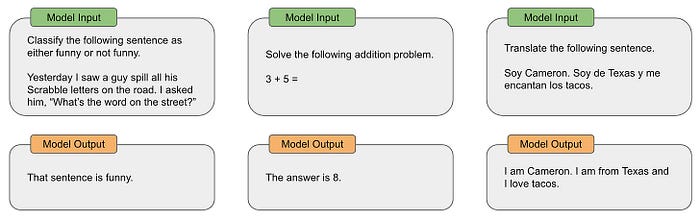
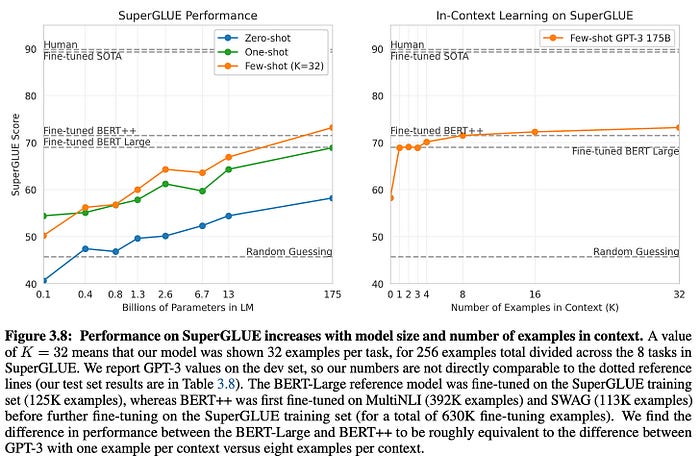
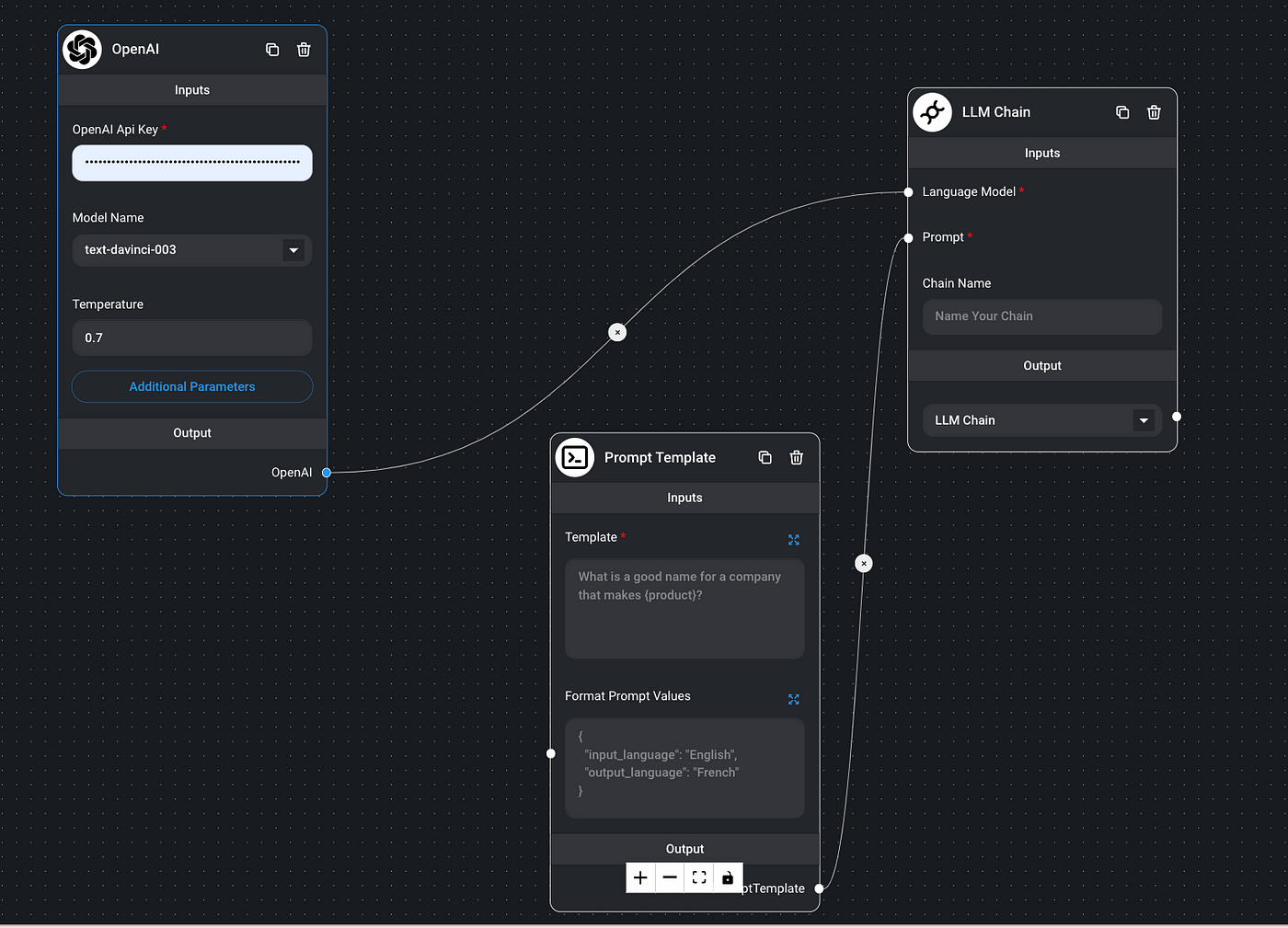
Llama 2是由AI研究公司Meta开发并发布的下一代大型语言模型(LLM)。它在2万亿个公共数据tokens上进行了预训练,旨在使开发人员和组织能够构建生成式人工智能工具和体验。Llama 2在许多外部基准上优于其他开源语言模型,包括推理、编码、熟练程度和知识测试。
Llama2可免费用于研究和商业用途,并可从Meta的网站下载。然而,如果你想在Mac M1设备上运行Llama2,并用你自己的数据训练它,你需要遵循一些额外的步骤。本文将指导您完成在Mac M1上设置Llama2的过程,并针对您的特定用例进行微调。
内容大纲
- 步骤1:安装所需的依赖项
- 步骤2:下载Llama2模型权重和代码
- 步骤3:微调Llama2与您自己的数据
- 步骤4:生成文本与微调Llama2模型
步骤 1:安装所需的环境依赖
要在Mac M1上运行Llama2,你需要安装一些依赖项,比如Python、PyTorch、TensorFlow和HuggingFace Transformers。您可以使用Homebrew或Anaconda来安装这些软件包(如果Python以后会成为你的主要开发语言,那么建议用Anaconda)。例如,要使用Homebrew安装Python 3.9,您可以在终端运行以下命令:
1 | brew install python@3.9 |
安装Mac M1的PyTorch,你可以按照下面的链接:https://pytorch.org/get-started/locally/#macos-version
安装Mac M1的TensorFlow,你可以按照下面的链接:https://developer.apple.com/metal/tensorflow-plugin/.
安装Hugging Face Transformers,你可以在终端运行以下命令:
1 | pip install transformers |
步骤2:下载Llama2模型权重和代码
要下载Llama2模型权重和代码,您需要在Meta的网站上填写表格并同意他们的隐私政策。提交表单后,您将收到一封电子邮件,其中包含下载模型文件的链接。你可以选择不同的Llama2型号,从7B到70B参数范围。微调的变体,称为lama-2-chat,针对对话用例进行了优化。
在本教程中,我们将使用Llama-2-chat-7B模型作为示例。您可以从这个链接下载模型权重和代码:https://ai.meta.com/llama/llama-2-chat-7B.zip。下载zip文件后,您可以将其解压缩到首选目录中。你应该看到一个名为llama-2-chat-7B的文件夹,其中包含以下文件:
- config.json: 模型的配置文件。
- pytorch_model.bin: PyTorch模型权重文件。
- tokenizer.json: 模型的标记器文件。
- vocab.txt: 模型的词汇表文件。
- run_generation.py: 用模型生成文本的Python脚本。
步骤3: 用自己的数据微调Llama2
要用您自己的数据对Llama2进行微调,您需要准备一个包含您的训练数据的文本文件。文件中的每一行都应该包含一个对话回合或一个模型指令。例如,如果您想为客户服务聊天机器人微调Llama2,您的训练集文件可能看起来像这样:
1 | USER: Hi, I have a problem with my order. |
您可以将训练文件作为train.txt保存在与模型文件相同的目录中。然后,您可以在终端中运行以下命令,使用您的训练数据对Llama 2进行微调:
1 | python run_generation.py --model_type gpt2 --model_name_or_path ./llama-2-chat-7B --train_data_file ./train.txt --output_dir ./llama-2-chat-7B-finetuned --do_train --per_device_train_batch_size 1 --gradient_accumulation_steps 4 --learning_rate 5e-5 --num_train_epochs 3 --save_steps 1000 --save_total_limit 1 |
该命令将使用以下参数微调Llama 2:
- model_type:模型类型,对于Llama 2,为gpt2。
- model_name_or_path:模型目录的路径,在此例中为。/ lama-2-chat- 7b。
- train_data_file:训练数据文件的路径,在此例中为。/train.txt。
- output_dir:输出目录的路径,将保存微调模型,在本例中为。/ lama-2-chat- 7b - fintuned。
- do_train:一个标志,表示我们想要训练模型。
- per_device_train_batch_size:每台设备用于训练的批处理大小,在本例中为1。
- gradient_accumulation_steps:在执行向后/更新传递之前累积梯度的步数,在本例中为4。
- learning_rate:训练的学习率,在本例中为5e-5。
- num_train_epochs:训练模型的epoch数,在本例中为3。save_steps:每个检查点保存之间的步数,在本例中为1000。
- save_total_limit:要保留的最大检查点数,在本例中为1。
您可以根据需要和可用资源调整这些参数。请注意,微调Llama 2可能需要很长时间,并且需要大量内存和计算能力,特别是对于较大的模型。您可以通过查看打印在终端上的日志来监控培训过程的进度。
步骤4: 生成文本与微调Llama2模型
在用自己的数据对Llama 2进行微调后,在终端运行以下命令,可以使用微调后的模型生成文本:
1 | python run_generation.py --model_type gpt2 --model_name_or_path ./llama-2-chat-7B-finetuned --length 100 --prompt "USER: Hi, I want to cancel my subscription." |
该命令将生成具有以下参数的文本:
- model_type: 模型的类型,对于Llama2来说是gpt2。
- model_name_or_path:微调模型目录的路径,在本例中为./llama-2-chat- 7b - fintuned。
- length: 生成文本的最大长度,在本例中为100个tokens。
- prompt: 模型的文本输入是“USER:嗨,我想取消订阅。在这种情况下。
您可以根据自己的需要和偏好更改这些参数。您还可以通过使用 - no_cuda标志并在终端中输入文本输入来与模型进行交互。例如:
1 | python run_generation.py --model_type gpt2 --model_name_or_path ./llama-2-chat-7B-finetuned --length 100 --no_cuda |
最后
Llama2是一个强大而通用的大型语言模型,可用于各种生成和会话AI应用程序。通过使用您自己的数据对其进行微调,您可以针对您的特定用例对其进行定制,并改进其性能和相关性。我希望你发现这篇文章有帮助和信息。
原文:How to Run Llama 2 on Mac M1 and Train with Your Own Data